
Collection of online resources for AVSR

Collection of online resources for AVSR
Papers and implementations
Below is the collection of papers, datasets, projects I came across while searching for resources for Audio Visual Speech Recognition.
Paper I am trying to implement, Lip Reading Sentences in the Wild.
PyTorch implementation of SyncNet based on paper, Out of time: automated lip sync in the wild Keras implementation here.
Keras implementation of LipNet based on paper, LipNet: End-to-End Sentence-level Lipreading.
Lip Reading in the Wild using ResNet and LSTMs in Torch based on paper, Combining Residual Networks with LSTMs for Lipreading PyTorch implementation of same, Lip Reading in the Wild using ResNet and LSTMs in PyTorch
Not a speech to text system but to match lip video with corresponding audio. Lip Reading - Cross Audio-Visual Recognition using 3D Architectures in TensorFlow based on paper, 3D Convolutional Neural Networks for Cross Audio-Visual Matching Recognition.
Keras implementation of Vid2speech based on paper, Vid2Speech: Speech Reconstruction from Silent Video project site here.
TensorFlow implementation of a seq2seq model for Speech Recognition not a visual speech recognition but audio speech recognition based on paper, Listen, Attend and Spell. This was an improvement over DeepSpeech by using seq2seq architecture with attention mechanism. Also the architecture is similar to the audio only part of Lip Reading Sentences in the Wild (LRW) model.
A recently released paper from the authors of lip reading in the wild and lip reading using ResNet, Deep Lip Reading: a comparison of models and an online application. The focus is on using Spatio-Temporal 3D CNN to extract visual features.
Datasets
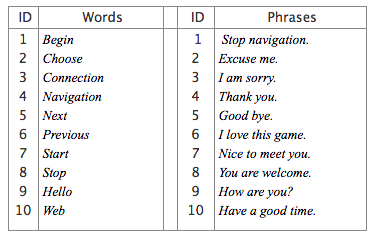
Miracl VC-1 corpus. Fifteen speakers utter ten times a set of ten words and ten phrases (see the table below):
Lip Reading in the Wild (LRW) words dataset, The dataset consists of up to 1000 utterances of 500 different words, spoken by hundreds of different speakers. All videos are 29 frames (1.16 seconds) in length. (Need to obtain permission before downloading)
Lip Reading in the Wild (LRW) sentences dataset, The dataset consists of thousands of spoken sentences from BBC television. Each sentences is up to 100 characters in length. (Need to obtain permission before downloading)
The GRID audiovisual sentence corpus the corpus consists of high-quality audio and video (facial) recordings of 1000 sentences spoken by each of 34 talkers (18 male, 16 female). Sentences are of the form “put red at G9 now”. The corpus is together with transcriptions.
Leave a Comment